In this case, my objective was to extract specific data from one of my blog posts, so I can use Zapier to automatically share the post for me on social media.
I started by creating a Push trigger, that will allow me to manually start my script on an open web page using the Chrome extension for Zapier.
From here, I added a new action of the “Code” type, and configured it to pass through the URL from the push trigger.
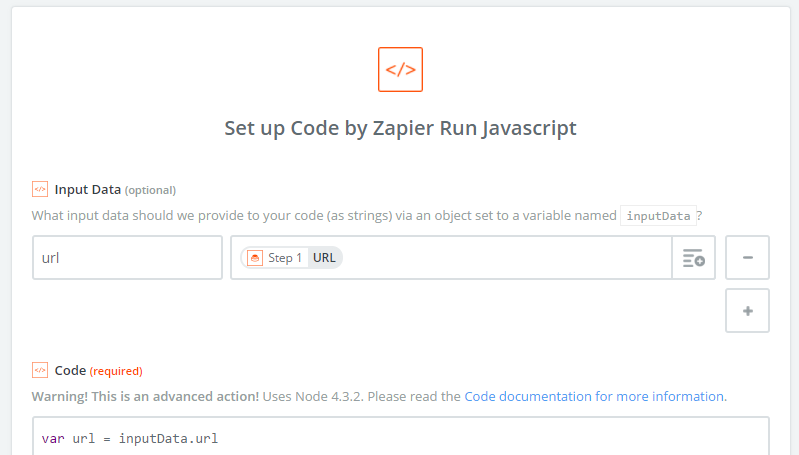
I added the following code to download the web page and extract my data:
var url = inputData.url
if (url.match(/zapier\.com/)) {
url = 'https://tobico.net/post/2017/05/2dremix-devblog-2-saving-and-image-editing/'
}
fetch(url)
.then(res => res.text())
.then(body => {
const name = body.match(/<h1[^>]*>([^<]+)<\/h1>/)[1]
const imageURL = body.match(/<p><img src="([^"]+)"/)[1]
var output = { url, name, imageURL, rawHTML: body }
callback(null, output)
})
.catch(callback)
Let’s walk through what’s going on here step-by-step:
var url = inputData.url
if (url.match(/zapier\.com/)) {
url = 'https://tobico.net/post/2017/05/2dremix-devblog-2-saving-and-image-editing/'
}
Gets the url configured in input data and puts it in a variable. I then check if the URL matches the Zapier website and if so, replace it with my testing URL. This seems to be necessary since in test mode, Zapier will always use the URL of the current page (the Zapier editor) as the URL for push actions.
fetch(url)
.then(res => res.text())
.then(body => {
...
callback(null, output)
})
.catch(callback)
This is almost directly out of the Zapier scripting guide, changed only in that I converted it to use a more modern ES6 syntax. It fetches a page from the web by its URL, extracts the body text, and passes a result back to Zapier.
const name = body.match(/<h1[^>]*>([^<]+)<\/h1>/)[1]
const imageURL = body.match(/<p><img src="([^"]+)"/)[1]
These are some simple regular expressions to extract the data that I care about. Teaching you about regular expressions is beyond the scope of this post, but I’d highly recommend learning them if you’re at all interested in automation. RegexOne looks like a nice friendly guide.
To test my regular expressions, I opened the Chrome developer tools on my target page, and ran the following in the console:
document.body.innerHTML.match(/<h1[^>]*>([^<]+)<\/h1>/)
This approach allowed me test out my regular expressions without going through the full cycle of saving and testing in Zapier.
I used substrings (the round brackets) to delineate the part of the match I
wanted to extract into Zapier, and added [1] after the statements to pass back only the
substring value that I care about.
var output = { url, name, imageURL, rawHTML: body }
This final statement combines the values I care about into a hash to return to Zapier. I’m using the new ES6 object literal shorthand to include each of my extracted variables in the output.
I think this is a fairly simple - albeit brittle - approach to extracting web page data in Zapier. This is a great way to get data from a web page quickly into your Zapier flow, and in this particular case I can trust that it will be quite reliable - since I’m scraping my own website, I’m fully in control of how it’s rendered and don’t have to worry about the format changing unexpectedly.